

Best Practices with MicroStrategy
To get the best performance out of your MicroStrategy/Any system, you must be familiar with the characteristics of your system and how it performs under different conditions. In addition to this, you need a plan for tuning the system.
High level overview of tuning the system, you should follow below:
- Define the system requirements
- Deployment model
- # of Concurrent users
- # of Active Users
- Level of Performance
- Features expected (like scheduling a report, email deliver, mobile access, responsive design)
- Functionality expected (adhoc, pre-defined, prompted, page by, cubing)
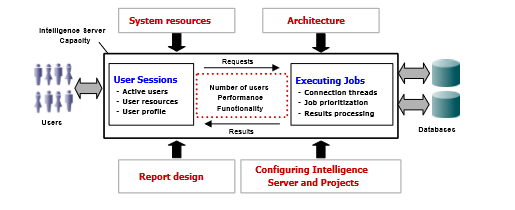
- Configuring System Design
- Main factors that affect System’s capacity are:
- System Resources available (including memory)
- Architecture of the system and network
- Design of the reports that are executed
- Configuration of server and projects to determine how system resources are used
- Main factors that affect System’s capacity are:
Pic Credit: MicroStrategy Knowledge Source – Admin PDF
How the data warehouse (DWH) can affect performance
DWH is a crucial component of the business intelligence system (BI). If it does not perform well, the entire system’s performance suffers.
- Platform considerations have to be planned well (size, speed of the machines hosting DWH/RDBMS)
- Design and tuning considerations (normalized, denormalized, fact tables, look up, aggregate tables, partition, index, stats collection, etc.,)
Network configuration best practices
MicroStrategy recommends the following best practices for network design:
- Place the web server machines close to the intelligence server machines
- Place intelligence server close to the both the data warehouse and the metadata repository
- Dedicate a machine for the metadata repository
- If you use Enterprise Manager(EM), dedicate a machine for the Enterprise Manager database (Statistics tables and data warehouse) – Note: EM is going away sooner (from 2020/2021), so recommend investing the separate machine for Platform Analytics
- If you have a clustered environment with a shared cache file server, place the shared cache file server close to the intelligence server machines
Managing System Resources
Intelligence server is the main component of the MicroStrategy system and hence , it is important to have that machines running it have sufficient resources for your needs. These resources include:
- The Processors (Windows Performance monitor
helps for monitoring)
- Processor Type, Speed and number of processors – key factors to consider
- Physical Disk characteristics
- Windows performance monitor to check % Disk Time (80% > to trigger alert)
- The amount of memory
- Windows performance monitor to monitor available memory
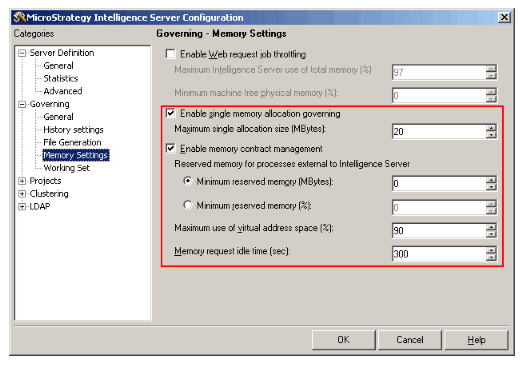
- Memory Contract Manager – governs below :
- Database requests
- SQL Generation
- Analytical engine processing
- Cache Creation and updating
- Report Parsing and serialization for network transfer
- XML generation
- Memory load of the requests governed by MCM depends on the amount of data that is returned from the DWH. Hence, memory load can’t be predicted.
- Graphing requests – MCM is not involved as they use predictable amount of memory
Pic Credit: MicroStrategy Knowledge Source
Governing parameters for tuning
We have got several factors to govern both Intelligence Server & Project level.
Intelligence Server Level

Export Governing parameters at Intelligence Server level

Governing Rules for Memory Settings

Project Level Governing Parameters

Project Level – Job Governors

Project Level – User sessions governing option

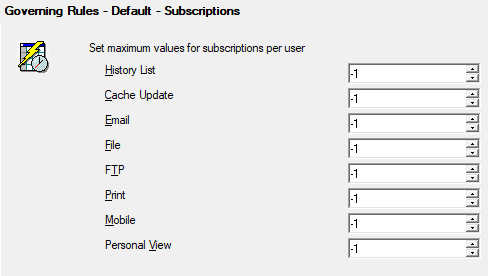
Project level – Subscription governors
Project level – import data option governors

Job Prioritization
Job priority defined the order in which jobs are processed. Jobs are usually executed as first-come, first-served.
Job priority does not affect the amount of resources a job gets once it is submitted to the data warehouse. Rather, it determines whether certain jobs are submitted to the data warehouse before other jobs in queue.
Connection Management
Connection Management is the process of setting the optimal number of default, medium, and high priority warehouse connections to support the Job executions on a given environment. This is based on user group, Job cost and project profiles. The overall goal of Job prioritization and connection management is to prioritize Jobs such that they can be run in a specified order.
Request Type: Report requests and element requests can have different priority. As of now, we don’t have any job prioritization for cube based jobs (i.e.) datasets created on top of cubes (dated: 2019)
Application Type: Jobs Submitted from different MicroStrategy applications, such as Developer, Scheduler, MicroStrategy Web, are processed according to the priority that you specify. No option to prioritize Mobile jobs exclusively as of now (dated: 2019)
User Group: Jobs submitted by users in the groups you select are processed according to the priority that you specify
Cost: Jobs with a higher resources cost are processed according to the priority that you specify. Job cost is an arbitrary value you can assign to a report that represents the resources used to process that job.
Project: Jobs submitted from different projects are processed according to the priority that you specify
Defining Priorities and Connections
Defining Priorities and Connections apply to all projects which use the selected database instance. A user can define Job priorities and number of connections on the Job Prioritization tab in the Database Instance editor, as displayed in the screen shot below:

Pic Credit: MicroStrategy Knowledge Source (KB8486)
Administrators can, based on priority, specify the number of warehouse connections that are required for efficient Job processing. There are three possible priorities for a Job: high, medium and low.
Administrators are not required to set medium and high connections, but must set at least one low connection, because low priority is the default Job priority.
The optimal number of connections is dependent on several factors, however the main criterion to consider when setting the number of connections is the number of concurrent queries the Warehouse Database can support.
MicroStrategy Intelligence Server processes a Job on a
connection that corresponds to the Job’s priority. If no priority is
specified for a Job, the MicroStrategy Intelligence Server processes the job on
a low priority connection. For example, Jobs with a high priority are
processed by high priority connections; Jobs with a low or no priority are
processed by a low priority connection.
In the case of multiple job priority entries matching the executing Job, the MicroStrategy Intelligence Server will use the Job priority specified for the priority map entry that has the maximum number of matching factors as specified in the following Knowledge Base document:
- KB30315 : How does the MicroStrategy Intelligence Server 9.x-10.x determine the priority of a report or document job when multiple job priorities are specified?
MicroStrategy Intelligence Server also engages in connection borrowing when
processing Jobs. Connection borrowing occurs when MicroStrategy Intelligence
Server executes a Job on a lower priority connection because no connections
with an equivalent priority is available for the Job at execution
time. For example, high priority Jobs can run on both medium and low
priority connections as well as the default high priority connections. In
this way, users and administrators can be assured that the highest priority
Jobs have access to all connection resources. Also, connection borrowing
reduces the waste of resources caused by idle connections.
For example, if a Job with a medium priority is submitted and all medium priority connections are busy processing Jobs, MicroStrategy Intelligence Server will process the Job on a low priority connection. When a Job is submitted and no connections are available to process it, either with the pre-selected priority or with a lower priority, MicroStrategy Intelligence Server places the Job in queue and processes it when a connection becomes available.
Note that connection borrowing is not a guarantee that higher priority Jobs will always execute before lower priority Jobs. For example, suppose there is a high priority Job and a low priority Job in the pending queue, and a low priority connection becomes available. There is no guarantee that either the high or low priority Job will execute on the low priority thread. The Job that gets chosen to be executed on the low priority thread will depend on the order in which the Jobs were placed in the internal pending queue.
User should note that even though Job priority is set at the database instance
level, in a clustered environment, it applies per Intelligence Server
machine. For example, if Administrators configure to have 2 low, 2 medium
and 2 high priority threads at the database instance level, it is expected to
see a total of up to 6 connections on each Intelligence Server.
Designing Reports
In addition to the fact that large reports can exert a heavy toll on system performance, a report’s design can also affect it. Some features consume more of the system’s capacity than others when they are used.
Some report design features that can use a great deal of system resources include:
Complex Analytic calculations (such as AvgDev)
Subtotals
Page By
Prompt Complexity
Report Services Documents
Intelligent Cubes
Development Best Practices
It is a vast topic. As MicroStrategy is an enterprise product and the way object design works within the tool is extensive. Shared below article by Nalgan experts – credit for posting such an vast and extensive article
Ref: KB Article
Design Challenges Tips & Best Practices
Post credit to Persistent Systems for writing this post in 2017
- Developing Multi Lingual Reports
- Developing Metadata for various business functions
- Improving Warehouse Performance
- Improving Report Performance
- Data Authorization
- Time Series Analysis in MicroStrategy
- Ad-hoc Report creation via Guided Process
Ref: KB Article
Object Migration Best Practices
Object Migration is the process of migrating or moving objects from one
environment to another environment. For example, the objects developed in a
development environment can be copied to a UAT environment to test and validate
the reports/dossiers.
Object Migration is a repeatable process and as such, it should be designed to be most efficient and followed by all involved resources to ensure simple and risk-free object synchronization. MicroStrategy Object Manager can help you manage objects as they progress through your project’s life cycle. Using Object Manager, you can copy objects within a project or across projects.
For a smooth and easy migration, it’s recommended to review the attached PDF containing Object Migration best practices.
Post credit to MicroStrategy Knowledge base article
Best Practices for Performance Test with Integrity Manager
The results of a performance test can be affected by many factors. The following best practices can help ensure that users get the most accurate results from a performance test:
- Performance comparison tests should be run as single-project
integrity tests. This reduces the load on Integrity Manager and ensures
that the recorded times are as accurate as possible.
To compare performance on two Intelligence Servers, MicroStrategy recommends following the procedure below: -
- Perform a single project test against one project, saving the performance results.
- Perform a single project test against the second project, saving the performance results.
- Compare the two performance results in a
baseline-versus-baseline test.
- Wait until the performance test is complete before attempting to
view the results of the test in Integrity Manager. Otherwise the increased
load on the Integrity Manager machine can cause the recorded times to be
increased for reasons not related to Intelligence Server performance.
- If using a baseline-versus-baseline test or a
baseline-versus-project test, make sure that the tests have processed the
reports/documents in the same formats. Execution times are not recorded
for each format, only for the aggregate generation of the selected
formats. Thus, comparing a baseline of SQL and Graph data against a test
of only SQL data is likely to give inaccurate results.
- If the Use Report Cache setting
is selected on the Select Execution Settings page of the
Integrity Manager wizard, make sure that a valid cache exists for each
report or document to be tested. Otherwise the first execution cycle of
each report/document takes longer than the subsequent cycles, because it
must generate the cache for the other cycles to use. One way to ensure
that a cache exists for each report/document is to run a single-project
integrity test of each report before you run the performance test.
Note: This setting only applies to reports. Integrity Manager does not use document caches.
- On the Select Execution Settings page of the Integrity
Manager wizard, make sure Concurrent
Jobs is set to 1.
This causes Intelligence Server to run only one report or document at a
time, providing the most accurate benchmark results for that Intelligence
Server.
- The Cycles setting on the Select Processing Options page indicates how many times each report or document is executed. A high value for this setting can dramatically increase the execution time of your test, particularly if you are running many reports or documents, or several large reports.
Best Practices for Increasing Performance of Publishing Large Intelligent Cubes
- Enable cube partitioning, the partition attribute should be the
attribute with more cardinality in the cube (more cardinality means the
attribute with more different elements, for example in the Tutorial
project the attribute Item or Customer).
Additionally, the number of partitions is based on the number of CPUs in the I-Server. It should always be the amount of CPUs divided by 2, for instance if there are 16 CPUs, the partitions should be 8. More information about cube partitioning can be found here: https://www2.microstrategy.com/producthelp/10.8/InMemoryAnalytics/WebHelp/Lang_1033/Content/InMemoryAnalysis/Partitioning_cubes.htm
- Under the VLDB settings for that cube, make sure that to increase the setting “Query Optimizations – Maximum Parallel Queries per Report” to the same value that is determined in the partitions. For instance, if it is determined there are 8 partitions in the cube, then the value of this VLDB setting should be 8.
- Under VLDB settings > Query Optimizations > Data
Population for Intelligent Cubes admins need to test all the following
options:
– Normalize Intelligent Cube data in the database.
– Normalize Intelligent Cube data in the database using relationship tables.
– Direct loading of dimensional data and filtered fact data.
For this point admins need to try the three options and see which one has better performance.
Note:
Make these modifications and re-publish
the cube to find out which combination gives better performance. Once the best
combination is determined, admins can test the deletion and see if the
performance improves there.